
Introduction
An obscure quirk of the /proc/*/mem pseudofile is its “punch through” semantics. Writes performed through this file will succeed even if the destination virtual memory is marked unwritable. In fact, this behavior is intentional and actively used by projects such as the Julia JIT compiler and rr debugger.
This behavior raises some questions: Is privileged code subject to virtual memory permissions? In general, to what degree can the hardware inhibit kernel memory access?
By exploring these questions1, this article will shed light on the nuanced relationship between an operating system and the hardware it runs on. We’ll examine the constraints the CPU can impose on the kernel, and how the kernel can bypass these constraints.
Patching libc with /proc/self/mem
So what do these punch-through semantics look like?
Consider this code:
#include <fstream>
#include <iostream>
#include <sys/mman.h>
/* Write @len bytes at @ptr to @addr in this address space using
* /proc/self/mem.
*/
void memwrite(void *addr, char *ptr, size_t len) {
std::ofstream ff("/proc/self/mem");
ff.seekp(reinterpret_cast<size_t>(addr));
ff.write(ptr, len);
ff.flush();
}
int main(int argc, char **argv) {
// Map an unwritable page. (read-only)
auto mymap =
(int *)mmap(NULL, 0x9000,
PROT_READ, // <<<<<<<<<<<<<<<<<<<<< READ ONLY <<<<<<<<
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (mymap == MAP_FAILED) {
std::cout << "FAILED\n";
return 1;
}
std::cout << "Allocated PROT_READ only memory: " << mymap << "\n";
getchar();
// Try to write to the unwritable page.
memwrite(mymap, "\x40\x41\x41\x41", 4);
std::cout << "did mymap[0] = 0x41414140 via proc self mem..";
getchar();
std::cout << "mymap[0] = 0x" << std::hex << mymap[0] << "\n";
getchar();
// Try to write to the text segment (executable code) of libc.
auto getchar_ptr = (char *)getchar;
memwrite(getchar_ptr, "\xcc", 1);
// Run the libc function whose code we modified. If the write worked,
// we will get a SIGTRAP when the 0xcc executes.
getchar();
}This uses /proc/self/mem to write to two unwritable memory pages. The first is a read-only page that the code itself maps. The second is a code page belonging to libc itself (the getchar function).
The latter is the more interesting test — it writes a 0xcc byte (the x86-64 software breakpoint instruction) which will cause the kernel to deliver a SIGTRAP to our process if executed. This is literally changing the executable code of libc. So the next time we call getchar, if we get a SIGTRAP, we know that the write has succeeded.
Here’s what it looks like when I run the program:

It worked! The middle print statements prove that the value 0x41414140 was successfully written and read from memory. The last print shows that a SIGTRAP was delivered to our process when we called getchar after patching it.
Here’s a video demo:
Now that we’ve seen how this feature works from the perspective of userspace, let’s dive a bit deeper. To fully understand how this works, we must look at how the hardware enforces memory permissions.
To the hardware
On x86-64, there are two CPU settings which control the kernel’s ability to access memory. They are enforced by the memory management unit (MMU).
The first setting is the Write Protect bit (CR0.WP). From Volume 3, Section 2.5 of the Intel manual:
Write Protect (bit 16 of CR0) — When set, inhibits supervisor-level procedures from writing into read- only pages; when clear, allows supervisor-level procedures to write into read-only pages (regardless of the U/S bit setting; see Section 4.1.3 and Section 4.6).
This inhibits the kernel’s ability to write to read-only pages, which is notably allowed by default.
The second setting is Supervisor Mode Access Prevention (SMAP) (CR4.SMAP). Its full description in Volume 3, Section 4.6 is verbose, but the executive summary is that SMAP disables the kernel’s ability to read or write userspace memory entirely. This hinders security exploits which populate userspace with malicious data to be read by the kernel during exploitation.
If the kernel code in question only uses approved channels for accessing userspace (copy_to_user, etc) SMAP can be safely ignored — these functions automatically toggle SMAP before and after accessing memory. But what about Write Protect?
With CR0.WP clear, the kernel implementation of /proc/*/mem will indeed be able to unceremoniously write to unwritable userspace memory.
However, CR0.WP is enabled at boot, and generally remains set for the life of a system. In this case, a page fault will be triggered in response to the write. As more of a tool to facilitate Copy-on-Write than a security boundary, this does not present any real restriction upon the kernel. That said, it does require the inconvenience of fault handling, which would not otherwise be necessary.
With this in mind, let’s examine the implementation.
How /proc/*/mem works
/proc/*/mem is implemented in fs/proc/base.c.
A struct file_operations is populated with handler functions, and the function mem_rw() ultimately backs the write handler. mem_rw() uses access_remote_vm() for performing the actual writes. access_remote_vm() does the following:
- Calls get_user_pages_remote() to lookup the physical frame corresponding to the destination virtual address.
- Calls kmap() to map that frame into the kernel’s virtual address space as writable.
- Calls copy_to_user_page() to finally perform the writes.
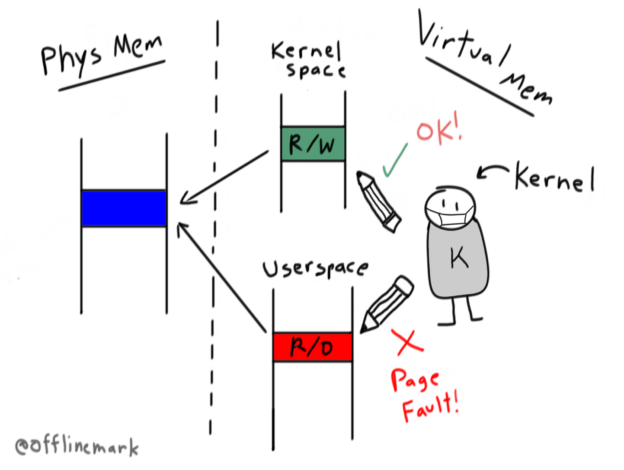
The implementation sidesteps the entire question of the kernel’s ability to write to unwritable userspace memory! It exerts the kernel’s control over the virtual memory subsystem to bypass the MMU entirely, allowing the kernel to simply write to its own writable address space. This renders the CR0.WP discussion moot.
To elaborate on each of these steps:
get_user_pages_remote()
To bypass the MMU, the kernel needs to manually perform in software what the MMU accomplishes in hardware. The first step is translating the destination virtual address to a physical address.
This is exactly what the get_user_pages() family of functions provides. These functions lookup physical memory frames that back a given virtual address range by walking the page tables. They also handle access validation and non-present pages.
The caller provides context and modifies the behavior of get_user_pages() via flags. Of particular interest is the FOLL_FORCE flag, which mem_rw() passes. This flag causes check_vma_flags (the access validation logic within get_user_pages()) to ignore writes to unwritable pages and allow the lookup to continue. The “punch through” semantics are attributed entirely to FOLL_FORCE. (comments my own)
static int check_vma_flags(struct vm_area_struct *vma, unsigned long gup_flags)
{
[...]
if (write) { // If performing a write..
if (!(vm_flags & VM_WRITE)) { // And the page is unwritable..
if (!(gup_flags & FOLL_FORCE)) // *Unless* FOLL_FORCE..
return -EFAULT; // Return an error
[...]
return 0; // Otherwise, proceed with lookup
}
get_user_pages() also honors copy-on-write (CoW) semantics. If a write is detected to a non-writable page table entry, an “page fault” is emulated by calling handle_mm_fault, the core page fault handler. This triggers the appropriate CoW handling routine via do_wp_page, which copies the page if necessary. This ensures that writes via /proc/*/mem are only visible within the process if they occur to a privately shared mapping, such as libc.
kmap()
Once the physical frame has been looked up, the next step is to map it into the kernel’s virtual address space with writable permissions. This is done through kmap().
On 64 bit x86, all of physical memory is mapped via the linear mapping region of the kernel’s virtual address space. kmap() is trivial in this case — it just needs to add the start address of the linear mapping to the frame’s physical address to compute the virtual address that frame is mapped at.
On 32 bit x86, the linear mapping contains a subset of physical memory, so kmap() may need to map the frame by allocating highmem memory and manipulating page tables.
In both of these cases, the linear mapping and highmem mappings are allocated with PAGE_KERNEL protection which is RW.
copy_to_user_page()
The last step is executing the writes. This is achieved through copy_to_user_page(), which is essentially a memcpy. Since the destination is the writable mapping from kmap(), this just works.
Discussion
To summarize, the kernel first translates the destination userspace virtual address to its backing physical frame via a software page table walk. Then it maps this frame into its own virtual address space as RW. Finally, it performs the writes using a simple memcpy.
What is striking about this implementation is that it does not involve CR0.WP. The implementation elegantly sidesteps this by exploiting the fact that it is under no obligation to access memory via the pointer it receives from userspace. Since the kernel is in complete control of virtual memory, it can simply remap the physical frame into its own virtual address space, with arbitrary permissions, and operate on it as it wishes.
This gets at an important point: the permissions guarding a page of memory are associated with the virtual address used to access that page, not the physical frame that backs the page. Indeed the notion of memory permissions is purely a consideration of virtual memory and does not pertain to physical memory.
Conclusion
Having thoroughly investigated the implementation details of /proc/*/mem’s “punch through” semantics, we can reflect on the relationship between the kernel and the CPU.
At first glance, the ability of the kernel to write to unwritable userspace memory raises the question: to what degree can the CPU inhibit kernel memory access? The manual does indeed document control mechanisms that would seem to limit the kernel.
However, under inspection these prove to be superficial constraints at best — mere roadblocks that can be worked around, or sidestepped altogether.
This post was cited:
- LKML: https://www.spinics.net/lists/linux-integrity/msg19215.html
- https://joev.dev/posts/unprivileged-process-injection-techniques-in-linux
- https://fa1lr4in.com/2022/05/10/CVE-2016-5195-dirtycow-linux%E6%9C%AC%E5%9C%B0%E6%8F%90%E6%9D%83%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/
- https://habr.com/ru/companies/vk/articles/559322/
Learn something new? Let me know!
Did you learn something from this post? I’d love to hear what it was — tweet me @offlinemark!
I also have a low-traffic mailing list if you’d like to hear about new writing. Sign up here:
Thanks to Jann Horn for explaining much of this to me. Thanks also to Peter Goodman and Ben Marks for reviewing earlier drafts of this post.
I spent about an hour poking around and trying to figure out how ” auto getchar_ptr = (char *)getchar;” gets the actual libc address of getchar, considering what I know of the GOT/PLT. From what I can tell from debugging and analyzing a binary from that source (and please correct me if I misinterpreted things), that line of code will cause my compiler to add getchar() to a list of functions it resolves immediately on startup (along with __libc_start_main and a few other necessary helper functions) so that the normal dynamic plt/got fill-in aren’t required.
I hadn’t thought of this, but it’s a great question. I didn’t investigate deeply but this sounds right to me. The compiler can emit a GOT read at the point when the function pointer is assigned, but in order to ensure that the GOT entry is filled in at this point, it needs to guarantee that the symbol has already been resolved. I’m not familiar with the mechanics of how functions get resolved immediately, that’s where my knowledge ends 🙂