Introduction
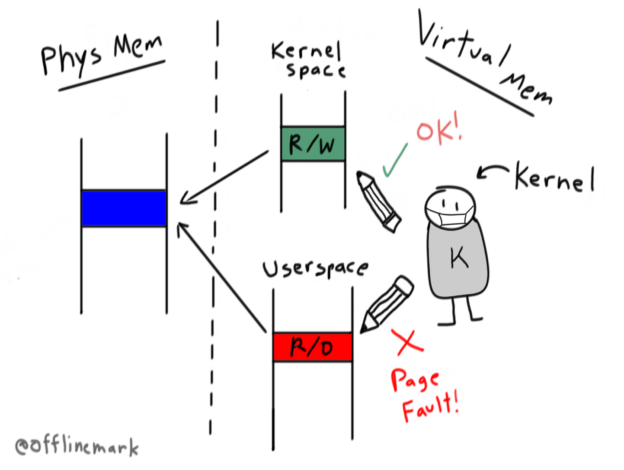
An obscure quirk of the /proc/*/mem pseudofile is its “punch through” semantics. Writes performed through this file will succeed even if the destination virtual memory is marked unwritable. In fact, this behavior is intentional and actively used by projects such as the Julia JIT compiler and rr debugger.
This behavior raises some questions: Is privileged code subject to virtual memory permissions? In general, to what degree can the hardware inhibit kernel memory access?
By exploring these questions1, this article will shed light on the nuanced relationship between an operating system and the hardware it runs on. We’ll examine the constraints the CPU can impose on the kernel, and how the kernel can bypass these constraints.
Continue reading