(This is not news; just something I was surprised to learn recently.)
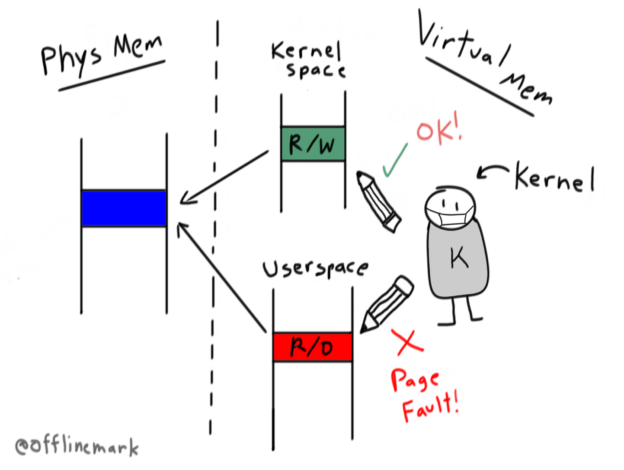
The classic virtual memory design for an operating system maps the kernel in the address space of every process. This improves context switch performance; switching into the kernel then requires no expensive page table reset. The kernel can run using the same page tables userspace was running with.
Typically, the kernel is mapped into the upper section of virtual memory. For example, on 32 bit Linux, the kernel is mapped into the top gigabyte. Concretely, to implement this, the page table entries mapping those kernel pages are set with the supervisor bit on. This means only privileged code (running in Ring 0 on x86) can access those pages. This is what enforces security and prevents userspace from accessing kernel memory. The MMU is therefore responsible for enforcing security.
In the world of CPU side-channel vulnerabilities this MMU enforced security boundary is no longer reliable. Specifically, the Meltdown vulnerability allows userspace to read arbitrary memory, anywhere in the virtual address space, regardless of whether the supervisor bit is set. It does this using cache-based timing side-channels that exist due to speculative execution of memory accesses.
This means that it’s no longer safe to map the kernel into the address space of userspace processes, and indeed that’s no longer done. The general name for this mitigation is “Kernel Page Table Isolation” (KPTI). As of “modern” kernels (since 5.15 for aarch64 Linux I believe),it’s on by default. (See CONFIG_UNMAP_KERNEL_AT_EL0). Context switches now must reset the page tables to a set private to the kernel.
KAISER will affect performance for anything that does system calls or interrupts: everything. Just the new instructions (CR3 manipulation) add a few hundred cycles to a syscall or interrupt. Most workloads that we have run show single-digit regressions. 5% is a good round number for what is typical. The worst we have seen is a roughly 30% regression on a loopback networking test that did a ton of syscalls and context switches.
https://lwn.net/Articles/738975/
The lesson here? Even the most seemingly fundamental knowledge about how computers work is subject to change. Don’t assume things are still as you learned them, and exercise caution and humility when discussing details of things you haven’t actively kept up with development of.
Links: