It’s worth it to learn to build your own tools. If you don’t, the only tools you’ll be able to use are those that someone else made, created a company around, then brought to mass market (henceforth, “the song and dance”).
That’s a herculean task, even for software tools which are the easiest to do all that with.
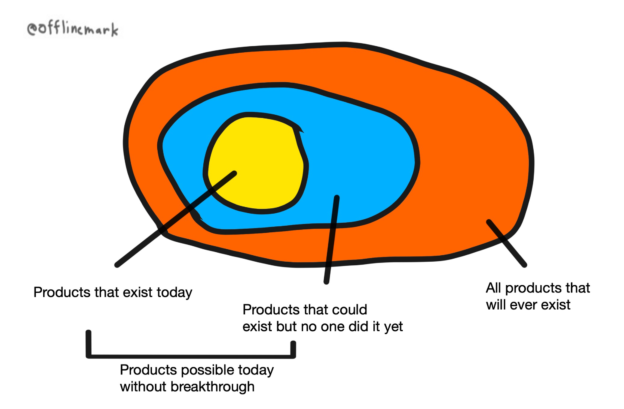
But just because someone didn’t do the song and dance (or failed at any of the infinite points to do so along the way, possibly even due to sheer bad luck) doesn’t mean that tool couldn’t exist today and be actively improving your life, right now.
There is a mind-boggling effort difference between making a prototype product that provides value today, and productionizing that product for the mass market and doing the song and dance.
Prototype products which are only ever used by the creator (i.e. expert user) for utilitarian reasons don’t need to have clean UIs, graceful error handling, or intuitive, consistent, and discoverable UX. They just need to kind of do the job.
The unreal effort required for mass market means that the actual products on the market today are only a tiny subset of the actual products possible in the world now without a technological breakthrough.
You, personally, would probably benefit from some of both sets of products; some that exist today on the market, some that could but no one did yet. Some of the latter might have even been game-changing for you.
But if you know how to build your own tools, you can access that superset of possible products today. Even if it’s just prototype quality tools, that might be good enough.
I’m talking mostly about digital tools but argument applies to anything. What I find especially interesting is how trends in technology continually decrease the effort to build prototype software. This used to require code. Then no-code came around. And finally AI generated code is here. People at large already do this today with tools like Excel, but I wouldn’t be surprised if many more people in the future are using bespoke one-off prototype mobile apps, desktop apps, and web software they’ve built for themselves to solve specific everyday problems.
Personally I do this a bunch already using code and no-code solutions:
And a few no-code apps I’ve built for myself using AppSheet:
- Personal metrics tracking app
- Simple personal finance and budgeting app
- Simple personal CRM
I’ve also created a custom calendar in Google Sheets which has really improved my life in 2023. Maybe I’ll write about that later.